
前言
如果你有使用過 Tensorflow(以下簡稱 TF),特別是很前期的 API,你有很高機率也經歷過一段痛苦的學習經驗,有這種體驗的你並不孤單,一方面是 TF low-level API 的使用邏輯不是很符合直覺(API 文件也寫得不是很清楚),另一方面是隨著 TF 的演進,同樣的目的,做法可能有好幾種,所以在網路上 google 程式碼的時候,可能會被各種不同的寫法搞得頭昏眼花(tf.layer、tf.estimator、tf.keras 或直接用 low-level API 實現),這些模模糊糊的觀念全部攪在一起,最後得到一團 TF 漿糊。

不過,TF 仍然是一個很強大的工具,也因為有這個工具,只要找到好的學習方法,使用得當,還是可以節省大家未來很多時間,所以,就讓我嘗試寫一篇文章,來試圖減緩一下 TF 的學習曲線吧!
這篇文章的目的純粹是為了降低 TF 的學習難度,如果你想直接用 PyTorch 等其他工具,那也很好。
入門建議
根據我使用過 Caffe、Tensorflow 跟 PyTorch 的經驗,我覺得能夠從 high-level API 入門是很重要的,因為剛開始實作各種 neural network(以下簡稱 NN),從最 high-level 的角度去看才能有掌握整體的感覺,所謂 high-level,就是你只需要看到這個 NN 的 input/output 是什麼、中間層有幾層、loss/optimizer 是什麼,然後就開始往你的目標前進。
以 tf.keras 的 API 舉例,假設你想要分類 MNIST dataset 裡面的手寫數字,最核心的 model 定義就像下面這樣(完整 source code 見此):
# 定義 model
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# 指定 loss、optimizer
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy'],
)
# 開始 train model:使用 ds_train dataset,跑 6 個 epoch
# 使用 ds_test 做 validation
model.fit(
ds_train,
epochs=6,
validation_data=ds_test,
)
是不是很直覺呢?原因是,上面的 code 跟你腦海中,NN 是怎麼建構、進而開始訓練的 flow 是很接近的。
可是,如果使用比較 low-level 的 API,你會不自覺地被迫離開 "只在乎 NN 基本 flow" 的狀態,同樣以一個可以分類 MNIST 數字的 model 為例,只是這次是用 low-level API(完整 source code 在此):
# 定義 model
def neural_net(x):
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])
out_layer = tf.matmul(layer_2, weights['out']) + biases['out']
return out_layer
# 建立 model 的輸出
logits = neural_net(X)
prediction = tf.nn.softmax(logits)
# 指定 loss、optimizer
loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=logits, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
# 把 optimizer 跟 loss_op 接起來(嗯,已經開始有點不直覺了,有 predictions、又有 loss_op、現在還要多一個 train_op,怎麼那麼多層)
train_op = optimizer.minimize(loss_op)
# 指定初始化 model 參數的負責人
init = tf.global_variables_initializer()
# 準備開始 training(hmmm....session 是啥?)
with tf.Session() as sess:
# 初始化 model 參數
sess.run(init)
for step in range(1, num_steps+1):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# 實際 training
sess.run(train_op, feed_dict={X: batch_x, Y: batch_y})
雖然乍看之下,大部分東西都一樣啊,可是,寫程式是一個很要求精確的心理活動,雖然只有幾個小地方閱讀起來不順暢,但這種不清楚知道所有事情的感覺會讓心裡的模糊資訊增加,最後就會讓更大的程式變成一團混亂。
你可能會說,上層的 API 把一堆東西都包起來,以透徹理解系統的角度來說,其實還不是很不精確?
確實沒錯。但是,我覺得使用工具的一個重點就在於,你不需要知道這個工具的所有細節,只要理解到一定程度,能利用這個工具達成目的就好,而包得好的 API 就是讓你很自然地不需要想到工具的細節。以筆電為例,如果你今天想要寫程式,你只需要開機、打開 IDE,就可以開始寫程式,是因為開機跟打開 IDE 都已經被包成很 high-level 的行為了。假設現在電腦還很原始,你為了開機,得找出對的電線,把對的電線接起來,還要插上開機磁碟,才能開機,寫程式這項 task 的複雜度是不是突然就上升很多?High-level API 的重點就在於降低 task 的複雜度,除非必要,不然你只要會按開機按鈕跟開 IDE 就好。
所以,我個人很推薦從 tf.keras 開始,因為他的 API 讓使用上很符合直覺,你就不需要費太多心思去管 high-level flow 以外的細節。事實上,這也是 TF 目前官方 tutorial 給初學者的建議,但基於我的經驗,還是希望把這段分析寫出來,如果你也曾經被 TF 嚇到過,tf.keras 是一個讓你重拾 TF 的好東西。
順帶補充一下,如果你有聽過 Keras,好奇 Keras 跟 tf.keras 的關係,可以看看這篇 - Keras vs. tf.keras: What’s the difference in TensorFlow 2.0?。但你如果懶得看,簡單 summary 就是,用 tf.keras 就對啦!
理解 computational graph
上面的 low-level API 範例中,有看到 session 這個東西,其實 session 這個東西,只要你了解 computational graph,就非常直觀,而這也是在寫 TF code 的時候一定要很清楚的基本觀念。
避免重複花時間說明別人已經講得很清楚的東西,直接上個影片,看完就能了解 computation graph 是什麼:

然後如何跟 session 的觀念接起來,請看:The Low/Mid-Level API: Building Computational Graphs and Sessions。用一句話說就是,先建立好 computation graph,然後 session 會執行你建立的 graph。
了解其他 API 的定位
TF 的其中一個強大之處,在於他有很多 API,但這也大大增加了這個工具的複雜度,讓學習曲線大幅變陡。而為了在學習新的 API、或是上網找各種解答時不混亂,心中有個大地圖是非常重要的:
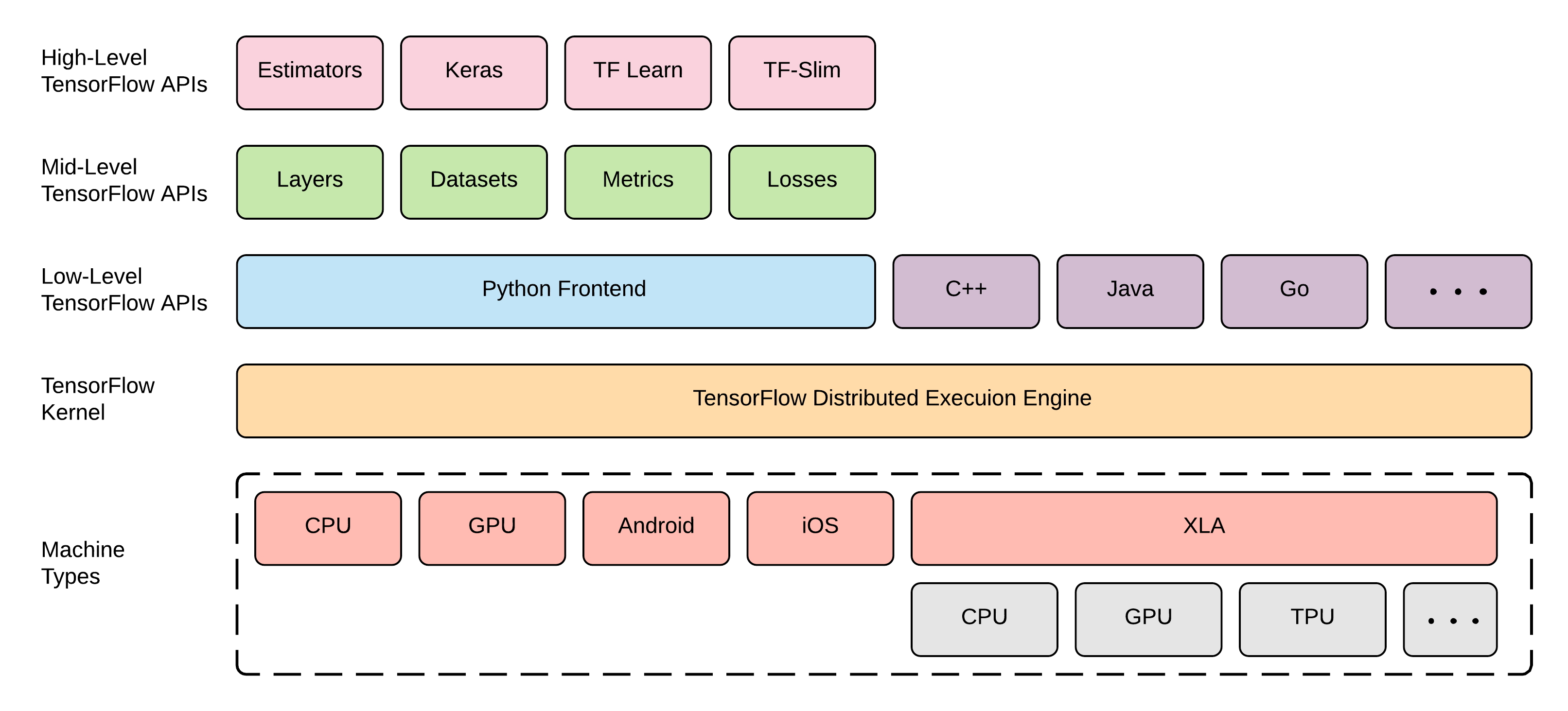
有這個大地圖,你未來在看到各種 API 就不會混亂,你可以先找出那個 API 的定位,想想是不是你需要的,如果不是你要的,那就不需要去弄懂,你也就不會有覺得有很多東西要學的混亂感。上圖出自 Ekaba Bisong 的網站。
最後建議 - 觀察你最想從什麼 project 開始玩
上面說了這麼多,歸根究底也只能稍微幫助大家更容易上手 TF。要能靈活應用,還是要動手多用 TF 去做你有興趣的 project,然後在過程中,自然會學會越來越多 TF 的細節,這樣你就能找到專屬於自己的 TF 學習道路!
總結
以上是我覺得要把 TF 學好的幾個重點,也鼓勵大家在看這篇文章的時候,meta-learning 一下,想想看自己有沒有學習其他東西很卡的經歷,如果有,那很卡的原因是什麼呢?能否也像上面拆解學 TF 很卡的原因一樣拆解開來?
例如你是不是從太困難的路徑開始學習,也許能找到其他教學或比較簡單的起點?還是你可能缺少了一些基本的重要觀念,使得很多東西看起來都不直覺?又或是你心中沒有一個大地圖能幫你定位看到的各種東西,所以你越學越混亂?
當你對 meta-learning 越來越有經驗,你就能越來越有效率地移除自己學習路上的障礙,不僅省下大量時間,也減少過程中的痛苦。祝大家都能越來越會 meta-learning,天天學習,天天開心!

延伸閱讀
- Machine Learning Zero to Hero (Google I/O'19)
- Tensorflow sucks
- Github repo: awesome tensorflow
- Are High Level APIs Dumbing Down Machine Learning?
- https://flamethrower.ai/
- IEEE Carleton Seminar - Building Learning Models on Google Cloud Platform
- TFRecord - TensorFlow 官方推薦的數據格式
- Day 7 / PyTorch / 深度學習框架之亂
![[ 作業檢討 ] 第一週超級挑戰題](https://anpan.coderbridge.io/2020/06/19/weekone-challenge-review/?utm_source=coderbridge-io&utm_medium=blog_related_post_img&utm_campaign=TechBridge 技術共筆部落格_[ 作業檢討 ] 第一週超級挑戰題_@yunanpan_https://static.coderbridge.com/images/covers/default-post-cover-1.jpg)



_@s103071049_https://static.coderbridge.com/images/covers/default-post-cover-3.jpg)
