
前言
上一篇文章中,我們利用 Deeplearn.js 學習了 linear regression,從氣溫與紅茶的關聯性中預測銷量,這次就來練習在機器學習中另一個很基本的方法 - Logistic regression(邏輯分析)。
先來張 Demo 成果圖:
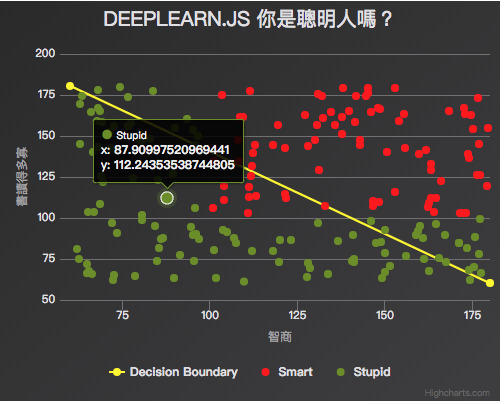
從成果圖中可以看出,所謂的 Logistic regression 與 Linear regression 最大不同就是,邏輯回歸大多用來進行分類,當結果只有兩種時,就是二元分類,當然也有多元分類,這邊以簡單二元分類來做練習。這次的範例參考自 【webAI】deeplearn.js的邏輯回歸
出發總要有個方向,做實驗總要有個想像
還記得小時候剛了解智商的概念時,很喜歡去查查名人們的智商數字,像是愛因斯坦、前美國總統布希等等,想看看這些名人的智商是多少,是不是真的很聰明才能像他們這樣成功。
今天假設我們有一群人的智商資料,現在想要利用這些資料分割出聰明人與笨蛋兩個分類,讓我們之後可以用來判斷一個人是聰明的率高一些,或是愚昧機率高一點,那我們該怎麼做呢?
這時候就可以出動 Logistic regression 來幫我們計算出一個預測模型,用來判斷該人的智商屬於哪個分類的機率比較高。
以迴歸分析來說,我們是希望能由給定一個固定的解釋變數 X,然後求出目標變數 Y 的平均值,是條件期望值的概念,若 Y 的結果是連續性的,我們就能試著透過線性模型去逼近一個剛好符合所有資料的公式。像是上一次的範例中,我們可以用線性模型求出在各種溫度下,紅茶的銷售狀況大約會是多少。
但有些時候,想求得的目標變數是二元或是多元的變數,像是剛剛例子中的聰明 或 笨蛋。如果硬要用線性函數去逼近的話,求得的結果通常會很差,像是下圖這般:
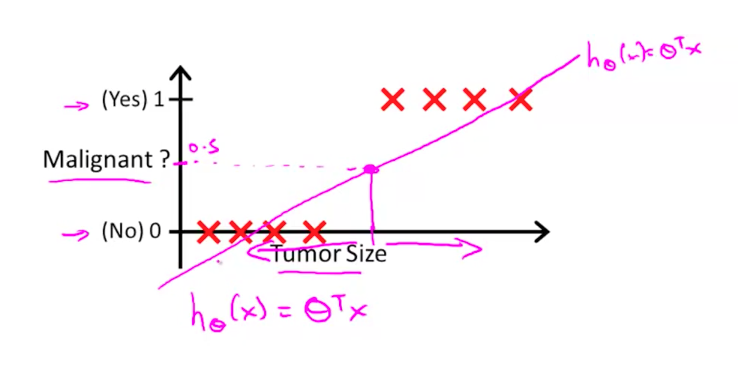
(圖片來源)
所以才有人提出用 sigmoid 這個能將數值侷限在 0 與 1 之間的函數來解決這個問題:
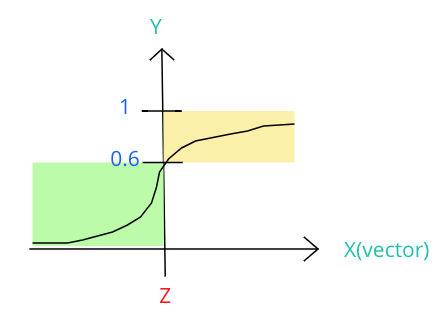
上圖就是一個 sigmoid function,假設我們今天判斷智商 180 代表機率 1 的狀況,而大於機率 0.6 時,就可以算是聰明人(黃色區域),而小於 0.6 的則屬於笨蛋(綠色區域),那今天我們的目標就是要找出一個 X 軸上的 Z 值,讓我們能根據 input 的 X 特徵值來判斷,若是 X 大於 Z 時,就可說他是聰明人(因為機率高於 0.6)。
這個讓我們找出 Z 值的函數就是我們要找的 Decision Boundary,也就是開頭 Demo 圖中的那條黃色線段!
有關於 Logistion regression 與 Decision Boundary 的詳細內容,我推薦大家閱讀這幾篇 blog,介紹得很簡單易懂:
Machine Learning 學習日記
你可能不知道的邏輯迴歸
大概了解 Logistic 後,那就來利用 deeplearn.js 找出 Decision Boundary 吧!
起手式,先來製作個假資料:
// 建立假資料,1 代表智商 100 分以上,0 代表智商 100 分以下
const data = []
for (let i=0; i<200; i++) {
let tmpX1 = Math.random() * 120 + 60;
let tmpX2 = Math.random() * 120 + 60;
data.push({
x: tmpX1,
y: tmpX2,
c: tmpX1 > 100 && tmpX2 > 100 ? 1: 0
});
}
我們隨機產生 200 組 training data,tmp_x 與 tmp_y 可以當作我們要輸入的 Input 特徵 X 向量,代表一個人的智商以及他閱讀的書籍量。
接著初始 deeplearn.js 的資料結構:
/**
* deeplearn.js 運算
*/
const x_list = [];
const y_list = [];
for (let elem of data) {
x_list.push([elem.x, elem.y]);
y_list.push(elem.c);
}
const x_data = dl.tensor2d(x_list);
const y_data = dl.tensor2d(y_list);
再次介紹一下,在 deeplearn.js 中,tensor 是最核心的資料結構,用來表示向量、矩陣或是多維度的資料。
有許多 utility function 可以輔助創建 tensor 資料結構,像是這邊用的是 tensor2d,也就是 2D (2-dimension) 的 tensor。
一個 tensor 其實包含三個成分,也是創建 tensor 時可以傳入的參數:
values (TypedArray|Array): tensor 的值。可以是 nested array 或 flat array 的結構。
shape(number[]):基本上就是該 tensor 的維度。若創建 tensor 時沒有指定維度,就會繼承傳入的 values 維度。也可以像這邊的範例一樣直接使用
tensor${1|2|3|4}d來創建dtype(float32'|'int32'|'bool):值的型別,當然是 optional。
由於我們要計算的 X 都是一組向量,所以這邊使用 dl.tensor2d 來建置一個二維的 tensor。
接著定義我們要 training 的係數,這邊取為 W 與 B:
// 權重 W 與偏差 B
const W = dl.variable(dl.zeros([1, 2]));
const B = dl.variable(dl.zeros([1]));
dl.variable(initialValue, trainable?, name?, dtype?) 用來創建 training 過程中需要的變數,也可透過參數指定該變數能否在 training 過程中被修改(trainable),預設是 true。
用 dl.zeros([1, 2]) 來創建一個 Shape 為 [1,2] 的填滿零值的 tensor 變數當權重 W,以及維度 1 的偏差變數 tensor B。
再來需要定義目標函數與 loss function:
// 定義目標函數 與 loss function (最一般的 mean square)
// logistic regression 模型
const f = x => dl.sigmoid(W.matMul(x.transpose()));
// loss function(log loss)
const loss = (pred, label) => dl.mean(dl.neg(dl.sum(dl.mul(label, dl.log(pred)))));
目標函數的部分其實就是帶入先前所提的 sigmoid function:
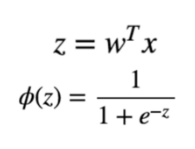
Z 就是我們要找的 boundary,就是權重與 input X 向量做矩陣乘法,所以這裡需要轉置矩陣 x.transpose()。
dl.sigmoid() 就是 deeplearn.js 提供的 sigmoid 函數(如上圖第二行)
將 Z 帶入 dl.sigmoid() 後就獲得了目標函數 f。
而 loss function 的話,一般在 logistic function 都是採用 log loss 的公式,詳細解釋與公式推導推薦閱讀此篇:
用人話解釋機器學習中的 Logistic Regression
照著公式很容易就可以帶出上述的 loss()。
最後就可以開始 training 我們的 data 啦:
// 梯度優化
const learningRate = 0.001
const optimizer = dl.train.sgd(learningRate)
// Training!
for (let i = 0; i < 1000; i++) {
optimizer.minimize(() => loss(f(x_data), y_data))
}
跟上一篇 linear regression 相同,我們採用dl.train.sgd,是 deeplearn.js 內建的 sgd 演算法模型,接受一個 leanring rate 參數。在每一次的迭代中,係數都會不斷被更新,以找出最佳的結果,而這個 learningRate 參數是用來控制每一次的更新幅度。因此不能夠設得太大,也不能設得太小。
optimizer 可額外輸入兩個參數,分別控制 1. 是否回傳最後的 cost; 2. 限制只更新哪些變數。我們 for loop 1000 次後,利用 dataSync() 來將係數從 Tensor 讀出:
// 用 dataSync 取得 training 結果
const wPredict = W.dataSync();
const bPredict = B.dataSync();
console.log(wPredict, bPredict);
dataSync() 是 Synchronously 的,會 block Browser 的 UI thread,直到 data 被你讀出。另外還有個 Asynchronously 的 data() method,會回傳 promise,當讀取結束時再呼叫 resolves。
因為接下來要用 Highcharts 畫圖,所以需要採用 dataSync() 來 block 著 UI thread 等資料讀出後再繼續。
取出係數的值後,就能算出一條 Decision Boundary 並繪製出來!
根據算出的係數,畫出線條頭尾兩點:
// 計算切割線段
const data_line = [
[60, parseFloat((180 * wPredict[0] + bPredict[0])/wPredict[1])],
[180, parseFloat((60 * wPredict[0] + bPredict[0])/wPredict[1])]
];
console.log(data_line);
然後用 HighCharts 繪圖:
// 繪製圖形
const data_scatter1 = [];
const data_scatter2 = [];
for (let elem of data) {
if (elem.x > 100 && elem.y > 100) {
data_scatter1.push([elem.x, elem.y]);
} else {
data_scatter2.push([elem.x, elem.y]);
}
}
// Result
const options = {
title: {
text: 'deeplearn.js 你是聰明人嗎?'
},
xAxis: {
title: {
text: '智商'
},
min: 60,
max: 180
},
yAxis: {
title: {
text: '書讀得多寡'
},
min: 60,
max: 180
},
series: [
{
type: 'line',
name: 'Decision Boundary',
color: '#fff600',
data: data_line
},
{
type: 'scatter',
name: 'Smart',
marker: {
symbol: 'cross',
radius: 4
},
color: '#FF0000',
data: data_scatter1
},
{
type: 'scatter',
name: 'Stupid',
marker: {
symbol: 'cross',
radius: 4
},
color: '#6B8E23',
data: data_scatter2
}
]
};
// 图表初始化函数
const chart = Highcharts.chart('app', options);
最終成果
See the Pen DeeplearnJS-logistic-regression by Arvin (@arvin0731) on CodePen.
結論
再次使用 deeplearn.js 來實作 Machine Learing 演算法,發現真的要套用這些 library 已經非常容易了,但還是受限於對演算法與數學公式的理解與敏銳度,不過也是透過這樣的實作練習,逼迫自己去嘗試了解這些演算法背後的概念與數學,在過程中也不斷想起以前大學修離散數學的記憶,當時都不太懂要怎麼使用這些數學,現在知道後就能讀得津津有味,也是蠻有意思的!
資料來源
- 【webAI】deeplearn.js的邏輯回歸
- GitHub Deeplearnjs
- Deeplearn js API doc
- 用人話解釋機器學習中的 Logistic Regression
- Machine Learning 學習日記
- 你可能不知道的邏輯迴歸
- 機器學習-支撐向量機(support vector machine, SVM)詳細推導
關於作者:
@arvinh 前端攻城獅,熱愛數據分析和資訊視覺化




![[Python] Using pre-commit to improve Code Readability Easily](https://jerryeml.coderbridge.io/2024/04/13/python-pre-commit-is-good/?utm_source=coderbridge-io&utm_medium=blog_related_post_img&utm_campaign=TechBridge 技術共筆部落格_[Python] Using pre-commit to improve Code Readability Easily_@jerryeml_https://static.coderbridge.com/images/covers/default-post-cover-3.jpg)
